Size Doesn’t Matter (Or Does It?)
Why large language models are out and small language models are in.

"Bigger is always better." This statement has been the motto for state-of-the-art language models in the last few years. In 2018, Google released BERT with 340 million parameters. In 2019, OpenAI released GPT-2 with 1.5 billion parameters. In 2020, OpenAI shocked the world by releasing GPT-3 with 175 billion parameters. And in 2022, Google released PaLM with 540 billion parameters. In general, the bigger the model, the better the performance. However, as we are entering the era of widespread adoption of artificial intelligence, the tech world has turned its attention from building ever larger models to getting more out of small language models.
Over the decades, researchers have tried many complex approaches to build better language models, but the bitter truth is that scaling simpler architectures achieves the best outcomes. The intuition behind this approach can be understood by the scaling hypothesis:
“The strong scaling hypothesis is that, once we find a scalable architecture like self-attention or convolutions, which like the brain can be applied fairly uniformly, we can simply train ever larger neural networks and ever more sophisticated behavior will emerge naturally as the easiest way to optimize for all the tasks & data. More powerful neural networks are ‘just’ scaled-up weak neural networks, in much the same way that human brains look much like scaled-up primate brains.”
There has been an increasing amount of evidence supporting this hypothesis—the most important being the emergence of abilities that the model was not intentionally trained on. In the natural world, emergent phenomena are complex outcomes, patterns, and behaviors that arise due to interactions between simple components. These phenomena exist in all kinds of domains, from the formation of snowflakes to the structuring of an ant colony. Similarly, with larger model sizes, more data, and more compute, language models transition from near-zero performance to nearly state-of-the-art performance at a rapid and unpredictable rate when they reach a critical scale. Interestingly, language models acquire skills that are often unrelated, like arithmetic, creative writing, and humor.
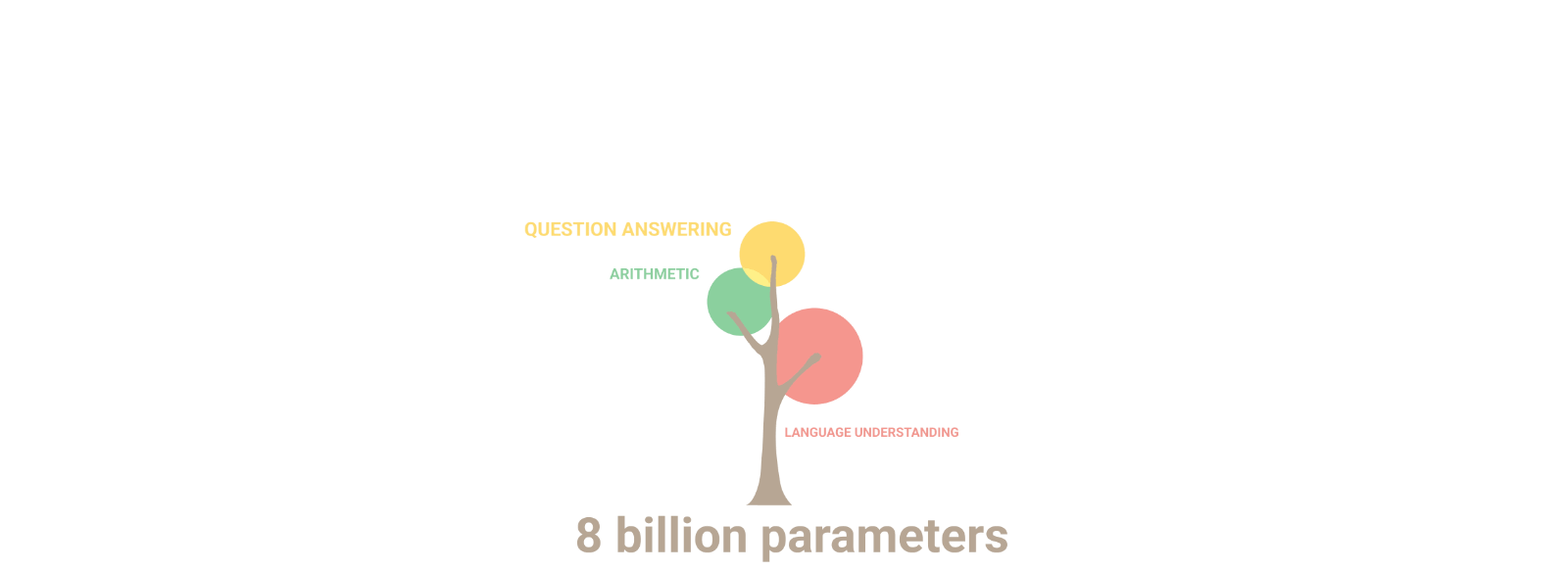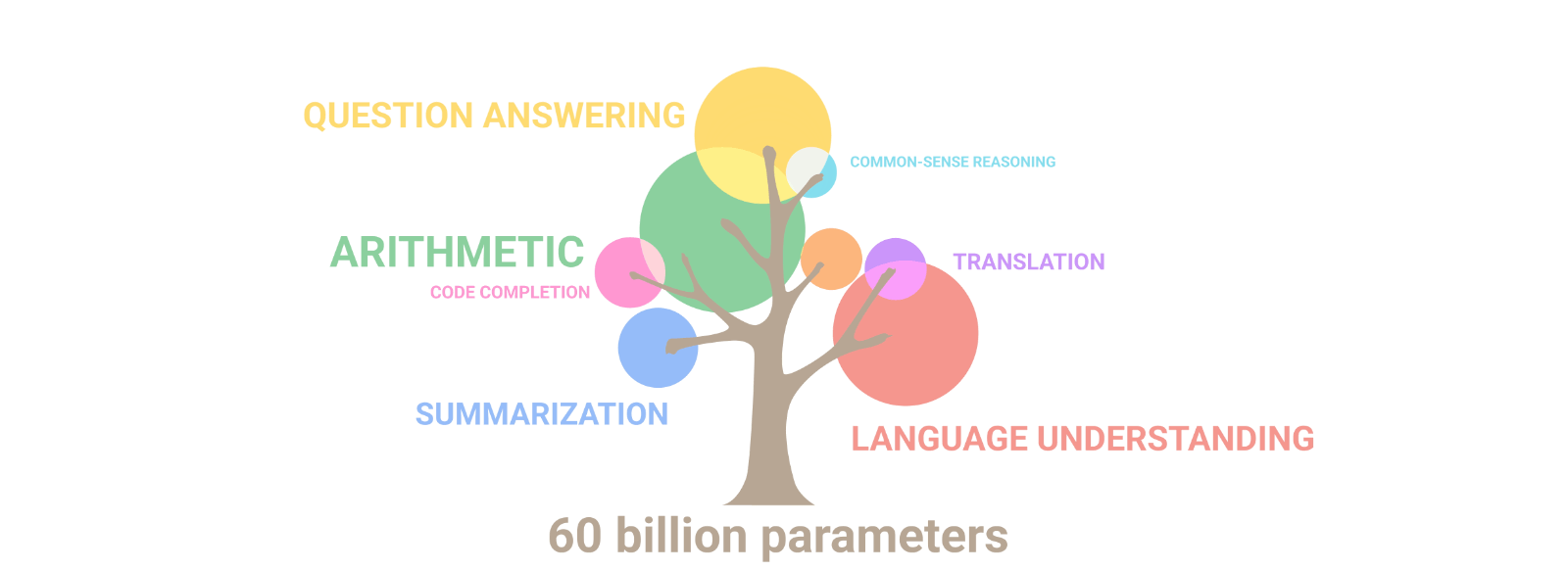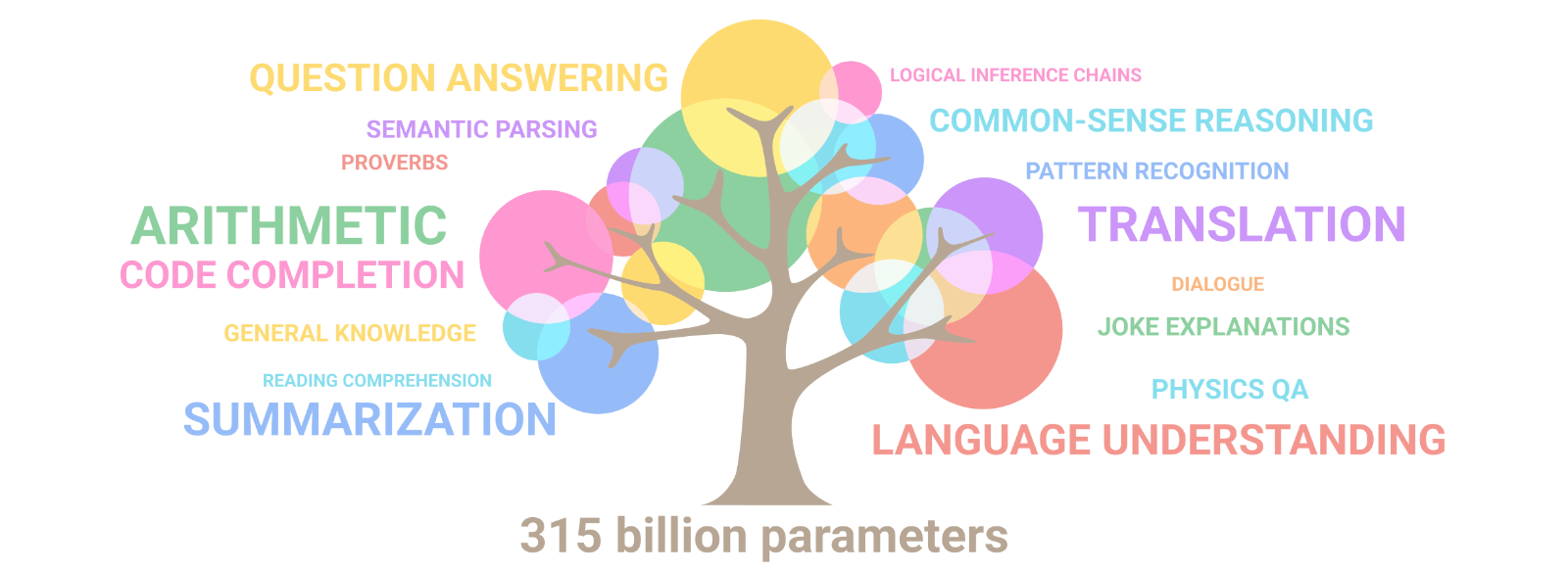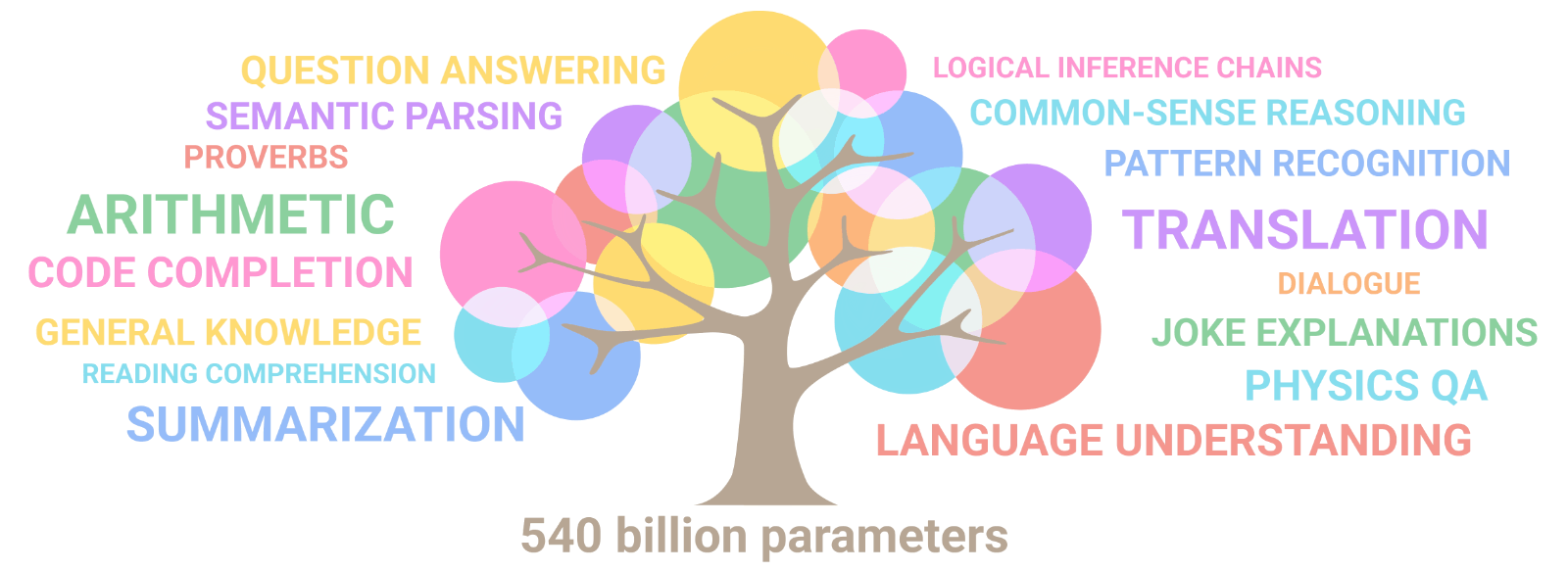
Source: Google Research — As the scale of the model increases, the performance improves across tasks while also unlocking new capabilities.
Even though large language models have been monumental in their achievements, surpassing Turing tests, their business applications almost never require the entire gamut of Artificial General Intelligence. Instead, businesses are focused on solving problems through specialized, narrowly focused tasks, coupled with the necessity to handle proprietary data securely. Moreover, the extravagantly high costs of these colossal models (capital, compute, energy) raise an important question: Can the essence of their advanced capabilities be captured within a smaller model? Smaller models, apart from offering cheaper training and lower compute requirements, allow for bespoke customization, domain-specific business logic, faster development cycles, and potentially on-premises deployment.
Since the real value proposition of using large language models stems from a deeper understanding of user intent, smaller language models can still usher in a new interaction paradigm with businesses employing different models for various tasks. For example, a customer service chatbot used for answering FAQs on a travel website doesn’t need the same kind of abilities or knowledge as one helping software developers write code faster. Additionally, smaller models allow businesses and hobbyists to easily fine-tune models to specific domains, distill knowledge into workflows, and use Retrieval Augmented Generation to query a secure, proprietary database—all without the cost of a large language model.
💎 Mighty Metric
Meta’s largest Llama-2 model was trained for 1,720,320 GPU hours. This roughly equals 196 years on a single GPU, or using 10,240 GPUs to complete training in 1 week!
In 2023, Microsoft released Phi-2, a small language model with only 2.7 billion parameters, trained on highly curated, AI-generated synthetic data to outperform models up to 25 times larger. Several other foundational models now come as a triad of different sizes—Meta’s Llama-2, Anthropic’s Claude 3, and Google’s Gemini, each sporting a small language model variant. Although the smaller model is eclipsed by its larger siblings in size, its performance is good enough for most people, especially considering that these models require less compute-intensive hardware to run. In fact, Google’s Gemini Nano is designed to run on mobile devices and powers the Pixel 8 Pro.
Amid the flurry of small language models, it is worth noting that the Specialist over Generalist paradigm works only because we have reached a tipping point in understanding natural language through artificial intelligence. What is often cited as the teacher-student paradigm, where training smaller models through synthetic data generated by larger models succeeds, is due to the emergent properties—showing that language models have learned how to learn. Only after achieving the critical scale and paying the upfront fixed cost of training large language models can we start to scale down and save on the variable costs of deploying small language models.